SQL语法、常见场景及示例
SQL的执行顺序
select子句,order by分别最后运行其他子句按书写顺序运行
SELECT <字段名>
FROM <表名>
JOIN <表名>
ON <连接条件>
WHERE <筛选条件>
GROUP BY <字段名>
HAVING <筛选条件>
UNION
ORDER BY <字段名>
LIMIT <限制行数>;
8.UNION:UNION连接的两个SELECT查询语句,会重复执行步骤1~7,产生两个虚拟表7,UNION会将这些记录合并到虚拟表8中。
SQL语法
1. 数据查询(SELECT)
SELECT column1, column2
FROM table_name;
2. 数据过滤和筛选(WHERE子句)
SELECT column1, column2
FROM table_name
WHERE condition;
3. 数据排序(ORDER BY子句)
SELECT column1, column2
FROM table_name
ORDER BY column1 ASC|DESC;
4. 数据分组和统计(GROUP BY子句)
SELECT column1, COUNT(*)
FROM table_name
GROUP BY column1;
5. 数据连接和关联(JOIN语句)
SELECT table1.column1, table2.column2
FROM table1
JOIN table2 ON table1.key = table2.key;
6. 条件逻辑(CASE语句)
SELECT column1,
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
ELSE default_result
END AS new_column
FROM table;
7. 数据修改(INSERT、UPDATE、DELETE)
INSERT INTO table_name (column1, column2) VALUES (value1, value2);
UPDATE table_name SET column1 = value1 WHERE condition;
DELETE FROM table_name WHERE condition;
8. 聚合函数(SUM、AVG、COUNT、MAX)
SELECT SUM(column1), AVG(column2), COUNT(*)
FROM table_name;
SELECT MAX(date_column) AS latest_date //获取最新日期!
FROM your_table;
常见场景及示例
1. 员工和部门管理
- 查询每个部门的平均工资,并按平均工资降序排列。
SELECT department_name, AVG(salary) AS avg_salary FROM employees e JOIN departments d ON e.department_id = d.department_id GROUP BY department_name ORDER BY avg_salary DESC; - 查询工资高于平均工资的员工。
SELECT * FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
2. 订单和产品管理
- 查询每个订单的总金额,并按总金额降序排列。
SELECT order_id, (SELECT SUM(quantity * unit_price) FROM order_details WHERE order_id = o.order_id) AS total_amount FROM orders o ORDER BY total_amount DESC; - 查询某个客户的订单总金额。
SELECT customer_id, SUM(total_amount) AS total_order_amount FROM orders WHERE customer_id = 1001 GROUP BY customer_id;
3. 产品和供应商管理
- 查询每个产品的供应商数量,并按供应商数量降序排列。
SELECT p.product_id, p.product_name, (SELECT COUNT(*) FROM product_suppliers ps WHERE ps.product_id = p.product_id) AS supplier_count FROM products p ORDER BY supplier_count DESC; - 查询每个产品的供应商信息。
SELECT p.product_name, s.supplier_name FROM products p JOIN product_suppliers ps ON p.product_id = ps.product_id JOIN suppliers s ON ps.supplier_id = s.supplier_id;
4. sum和case完成阶段统计
SELECT
SUM(CASE WHEN product_id = 1 THEN amount ELSE 0 END) AS total_sales_for_product_1,
SUM(CASE WHEN product_id = 2 THEN amount ELSE 0 END) AS total_sales_for_product_2,
SUM(amount) AS total_sales
FROM
sales;
表结构更新和数据迁移
思路:
- 先复制
- 再删除
- 后改名
-- 创建新的临时表
CREATE TABLE `rpa_app_temp` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '应用ID',
`app_name` varchar(255) COLLATE utf8mb4_general_ci NOT NULL COMMENT '应用名称',
`app_code` varchar(255) COLLATE utf8mb4_general_ci NOT NULL COMMENT '应用代码',
`business_type` varchar(255) COLLATE utf8mb4_general_ci NOT NULL COMMENT '业务类型',
`app_description` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci COMMENT '应用描述',
`refer_attachments` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci COMMENT '参考附件',
`version_id` int DEFAULT NULL COMMENT '当前版本ID',
`jar_url` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '当前版本JAR包地址',
`create_time` datetime NOT NULL COMMENT '创建时间',
`update_time` datetime NOT NULL COMMENT '更新时间',
`created_by` int NOT NULL COMMENT '创建人',
`updated_by` int NOT NULL COMMENT '更新人',
`is_enabled` tinyint(1) NOT NULL DEFAULT '1' COMMENT '启用状态((1:启用, 0:禁用))',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='RPA应用信息表';
-- 复制数据到临时表并为 created_by 和 updated_by 字段提供默认值
INSERT INTO `rpa_app_temp` (`app_name`, `app_code`, `business_type`, `app_description`, `refer_attachments`, `version_id`, `jar_url`, `create_time`, `update_time`, `created_by`, `updated_by`, `is_enabled`)
SELECT `app_name`, `app_code`, `business_type`, `app_description`, `refer_attachments`, `version_id`, `jar_url`, `create_time`, `update_time`, 0, 0, `is_enabled` FROM `rpa_app`;
-- 删除原始表
DROP TABLE `rpa_app`;
-- 将临时表重命名为原始表的名称
RENAME TABLE `rpa_app_temp` TO `rpa_app`;
删除重复数据
如何删除一张表中重复的数据,有两个字段相同就证明这条数据是重复的
在MySQL中,删除重复数据有多种方法。以下是一些常见的方法:
方法1:使用DELETE和JOIN
如果你有一个唯一标识列(比如id),你可以使用JOIN来删除重复的行。假设我们有一个表my_table,其中有两个列field1和field2,我们希望删除field1和field2都相同但id较大的记录。
DELETE t1 FROM my_table t1
INNER JOIN my_table t2
WHERE t1.id > t2.id AND t1.field1 = t2.field1 AND t1.field2 = t2.field2;
方法2:使用GROUP BY和HAVING
如果你没有唯一标识列,或者你想在不考虑其他列的情况下删除重复行,可以使用GROUP BY和HAVING子句。
DELETE FROM my_table
WHERE id NOT IN (
SELECT MIN(id) FROM my_table
GROUP BY field1, field2
);
这个查询首先选择每个field1和field2组合的最小id,然后删除那些不在这些最小id中的行。
方法3:创建新表🎯
把查询结果作为新表创建出来
如果你不想直接在原表上操作,可以先创建一个新表,将不重复的数据插入到新表中,然后删除原表,最后将新表重命名为原表名。
CREATE TABLE new_table AS
SELECT * FROM my_table
GROUP BY field1, field2;
DROP TABLE my_table;
ALTER TABLE new_table RENAME TO my_table;
请注意,在执行这些操作之前,最好先对数据库进行备份,以防万一操作失误导致数据丢失。
这些只是几种删除重复数据的方法,具体使用哪种方法取决于你的需求和数据库的具体情况。
小技巧:表结构转换Word表格查询SQL
SELECT
(@row_number:=@row_number + 1) AS 序号,
COLUMN_NAME AS 列名,
DATA_TYPE AS 数据类型,
CHARACTER_MAXIMUM_LENGTH AS 长度,
IS_NULLABLE AS 允许为空,
COLUMN_DEFAULT AS 默认值,
COLUMN_COMMENT AS 注释
FROM
information_schema.`COLUMNS`,
(SELECT @row_number:=0) AS t
WHERE
TABLE_SCHEMA = 'youlai_boot' -- 数据库名
AND
TABLE_NAME = 'rpa_app'; -- 数据库表名
运行该查询,然后在Navicat中选中所有结果右键复制为“制表符分隔值(字段名和数据)”
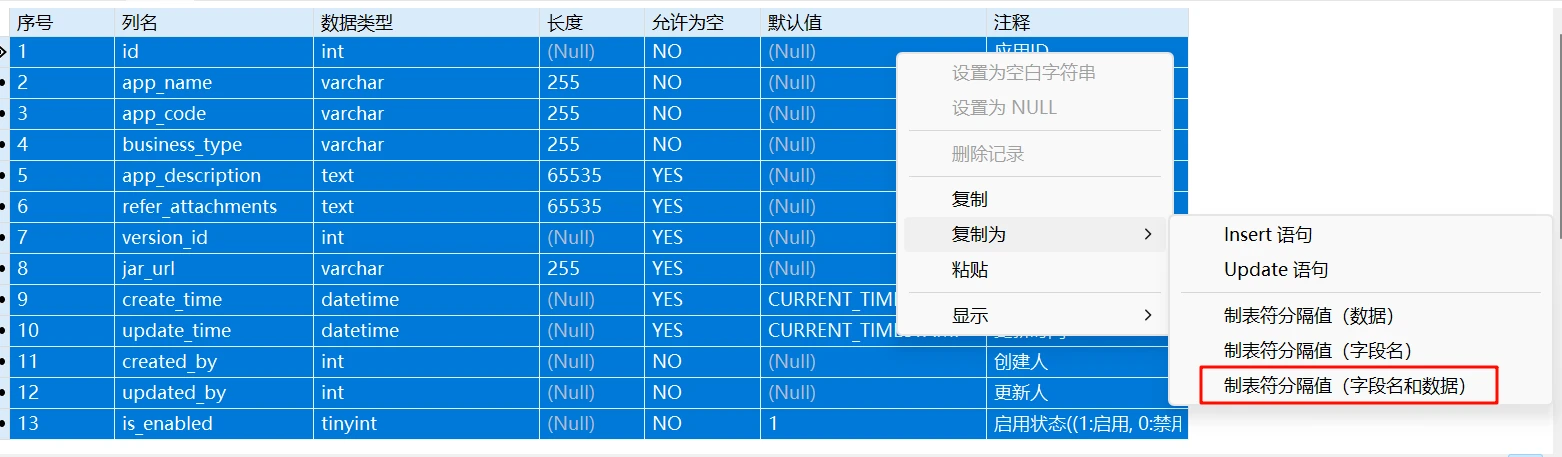
然后粘贴到Word文档中,最后在Word中文字转表格即可(选择按制表符分隔)
当然IDEA之类的工具运行上述的查询SQL也是可以的,然后将结果导出成Excel,复制导出Excel中的行列粘贴到Word中也能够被识别成表格,然后选择表格样式即可
Interactive Graph
Table Of Contents