前言
接着前面的构建多层感知模型进行手写数字识别项目取得的数据集和生成的感知机模型进行计算参数、训练参数的配置和优化然后训练并对训练结果进行验证、评估
配置模型参数
model.compile() 是 Keras 框架中用于配置深度学习模型训练的方法,它可以设置损失函数、优化器和度量指标等计算参数,
再将训练参数传递给 Keras 的 fit() 方法进行训练。以下是一个使用 model.compile() 配置模型训练的示例代码:
import tensorflow as tf
from tensorflow.keras import layers
model = tf.keras.Sequential([
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.CategoricalAccuracy()])
model.fit(x_train, y_train, epochs=5, batch_size=32)
在这个示例中,我们使用 model.compile() 方法设置了优化器、损失函数和度量指标。然后我们将训练数据(x_train和y_train)传递给 model.fit() 方法进行训练。
需要注意的是,model.compile() 方法只是一种配置深度学习模型训练的方法,而不是必须使用的方法。在其他深度学习框架中,也有其他的配置方法,比如 PyTorch 中的手动设置优化器、损失函数和度量指标等参数。
model.compile()配置计算参数

函数方法的这些参数都有默认值可以不写,但我们一般都会手动配置三个必要参数
-
loss:损失函数或目标函数,是网络中的性能函数,也是编译一个模型必须的两个参数之一
作为损失函数理解,他的实现有很多种,不止差值,还有可能是均方差等
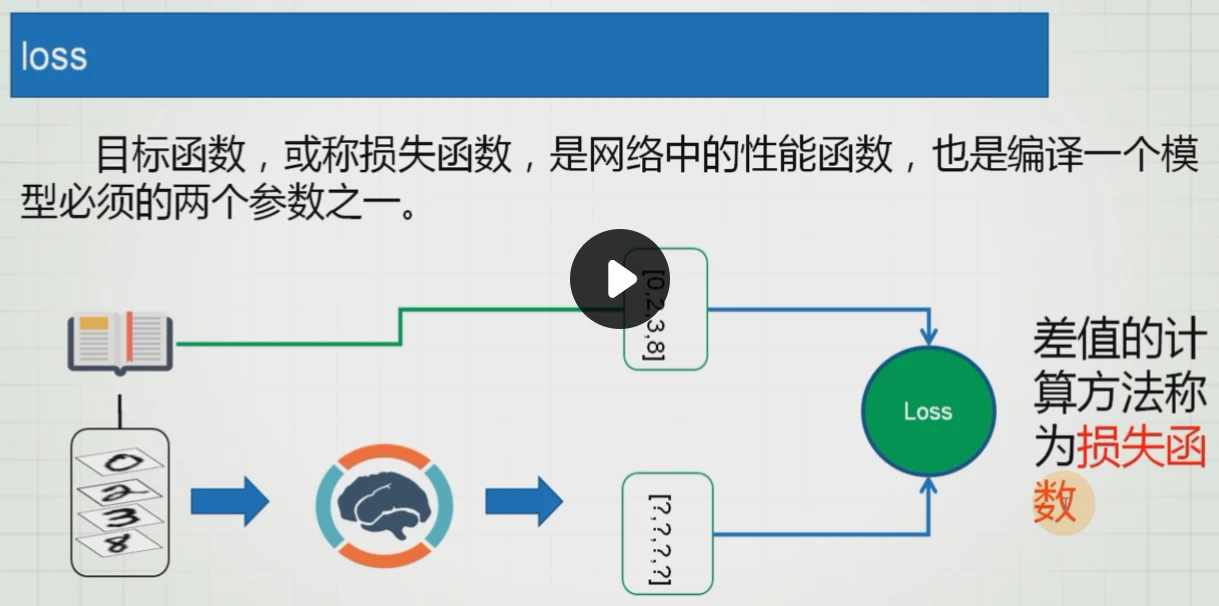
Keras内置了常见的预定义的损失函数,我们可一直使用损失函数名传参即可

-
optimizer:优化器是编译模型必要的两个参数之一。可以在调用model.compile()时传递一个预定义优化器名。也可以在调用model.compile()之前初始化一个优化器对象,然后传入该函数

优化器扮演的角色:(根据loss损失函数来)调整模型参数(使模型预测的结果更准确)的方法称为优化器
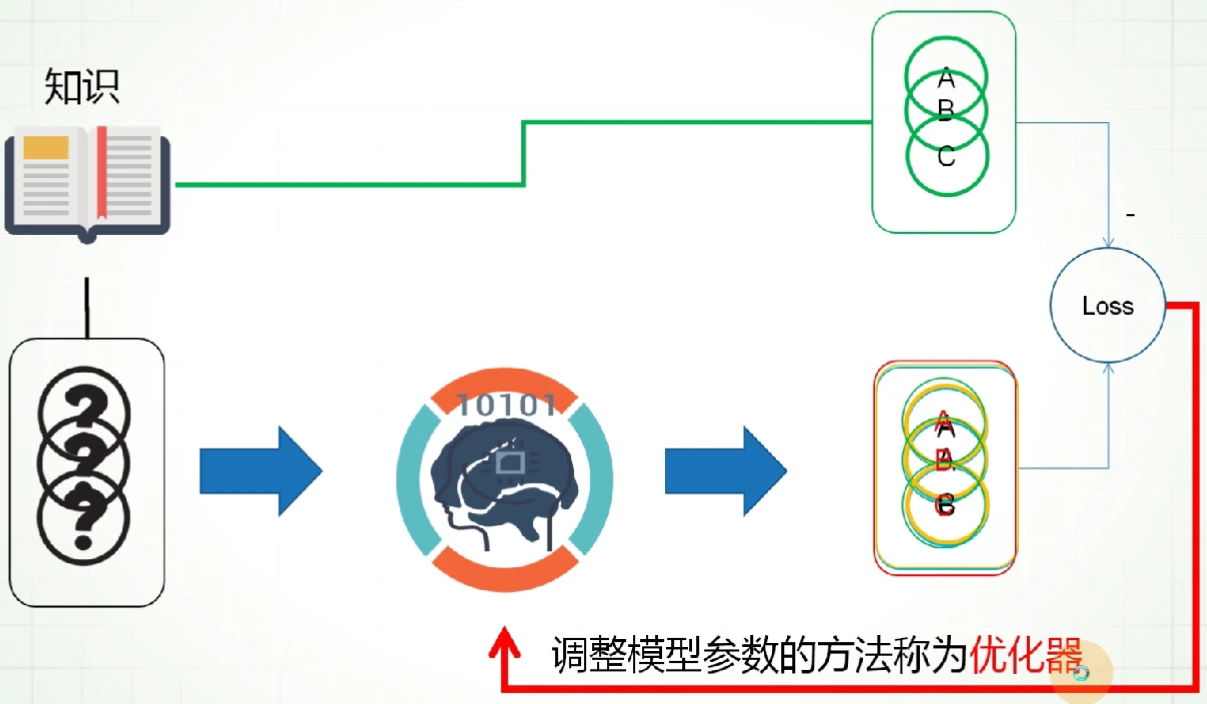
至于怎么调整不需要我来关心了(数据集很庞大涉及到以万计的参数),内置了不少常用的预定义的优化器
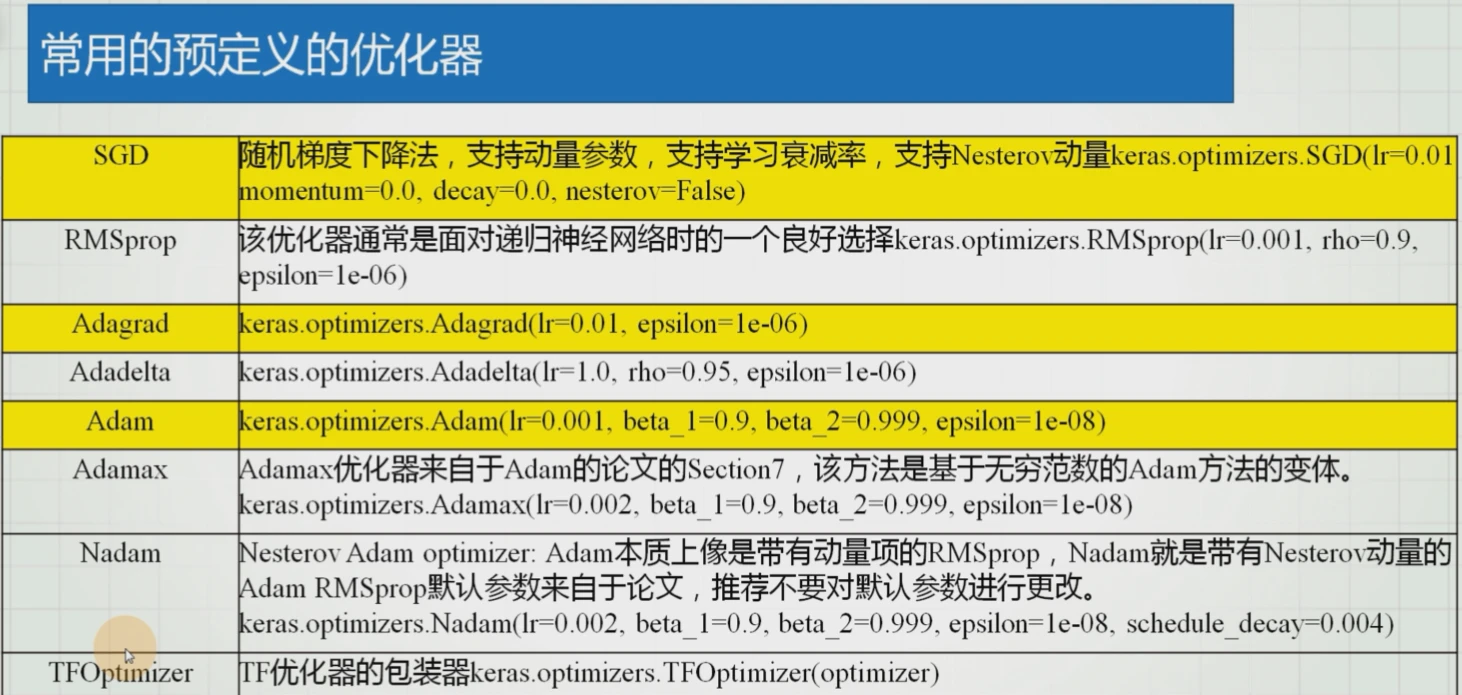
-
metrics:性能评估模块提供了一系列用于模型性能评估的函数这些函数在模型编译时由metrics关键字设置,性能评估函数类似于目标函数,只不过该性能的评估结果将不会用于训练。可以通过字符串来使用预定义的性能评估函数,也可以自定义一个Theano/TensorFlow函数并使用
model.fit()配置训练参数进行训练
调用model.fit()配置训练参数,开始训练,并保存训练结果(有返回值),
参数除了x、y外都有返回值,换句话说我们必须配置x和y的参数

fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况如果有验证集的话,也包含了验证集的这些指标变化情况
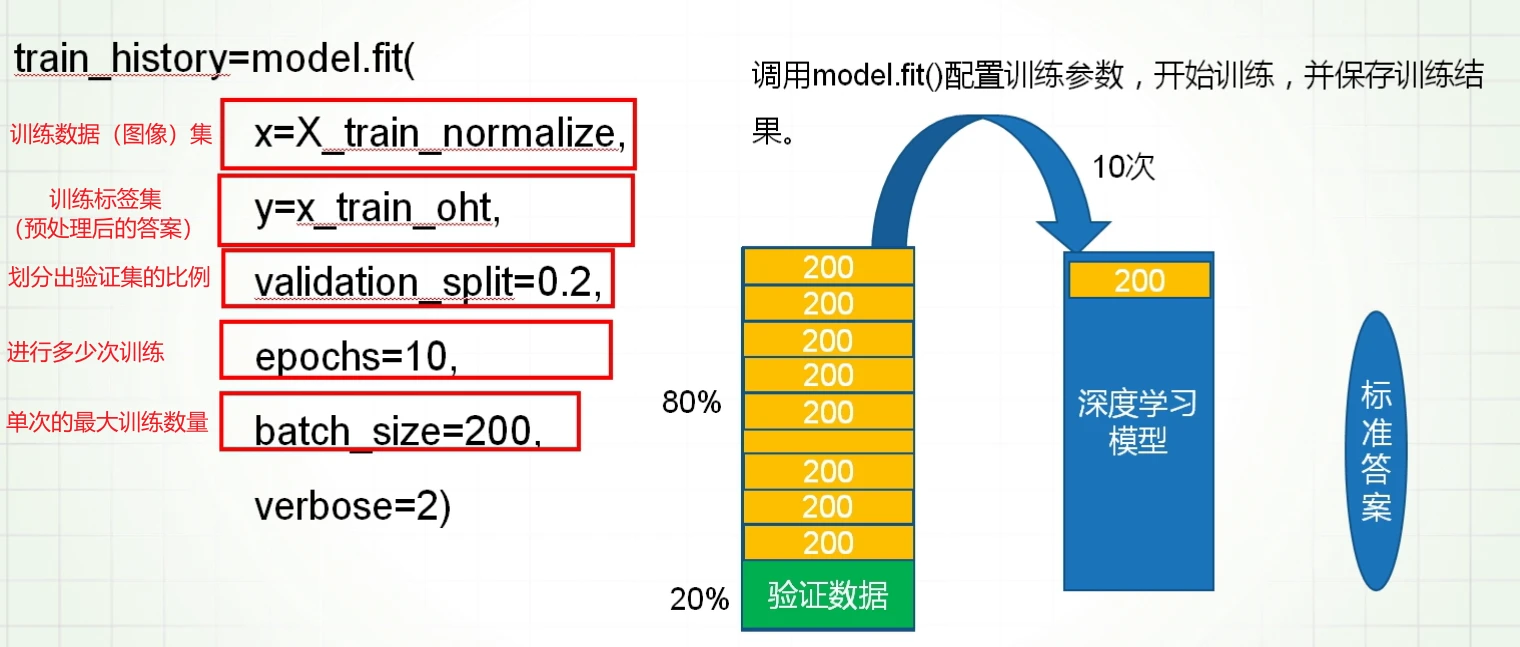
如上图所示,model.fit()配置训练参数有
-
x:训练数据集;y:训练标签集
-
validation:并不是训练数据全都用来用来,会划分一定比例的数据作为验证集,在训练过程中验证纠错配合损失函数等工作
-
epochs:指定训练多少次这些数据
-
batch_size:训练的数据是海量的,我们不可能都在一次训练过程完成哪怕单次的训练因为我们的硬件和算力跟不上,所以我们需要规定每次进入模型训练的最大数量
-
verbose:用于控制在训练过程中输出的信息量和详细程度。具体来说,
verbose参数可以设置为以下三种值:verbose=0:不输出任何信息,即静默模式。verbose=1:输出进度条和每个 epoch 的训练结果,包括损失函数和度量指标等。verbose=2:在每个 epoch 结束时输出一行训练结果,包括损失函数和度量指标等。
因此,当你设置
verbose=2时,会在每个 epoch 结束时输出一行训练结果,方便你观察模型的训练进展情况。这在调试模型时非常有用,可以让你及时发现模型出现的问题,并及时采取措施进行调整和改进。当然,如果你想要更加详细的训练信息,可以将verbose参数设置为 1,这样可以在训练过程中输出更多的信息,包括每个 batch 的训练结果等。
模型的训练与评估
训练过程设置了verbose=2可以看到训练时验证集的评估效果

但是这些都是训练验证集的效果并不能代表模型真正的效果
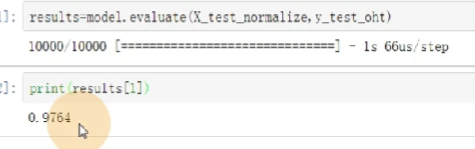
results=model.evaluate()
因为我们的测试集是完全没有参与训练的,我们需要使用测试集单独去评估我们模型的真正效果
model.evaluate()参数包括测试训练集和测试标签集

函数返回一个测试误差的标量值(如果模型没有其他评价指标),或一个标量的list(如果模型还有其他的评价指标)。model.metrics names将给出list中各个值的含义。

对使用模型进行预测model.predict_classes ()
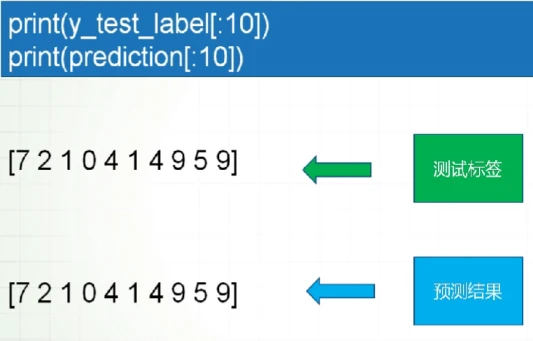
模型预测函数model.predict_classes ()用来对测试数据进行分类预测.其函数原型为:predict classes(X,batch size=128,verbose=1)函数返回测试数据的类预测数组,return :测试数据的标签数组

在假设不知道答案的情况下对测试集进行预测得到的类预测数组和测试标签数组(标准答案)进行比较,来看到模型的实际效果