深度学习开发框架
在实践中体验和学习深度学习的原理和构建方法、流程等
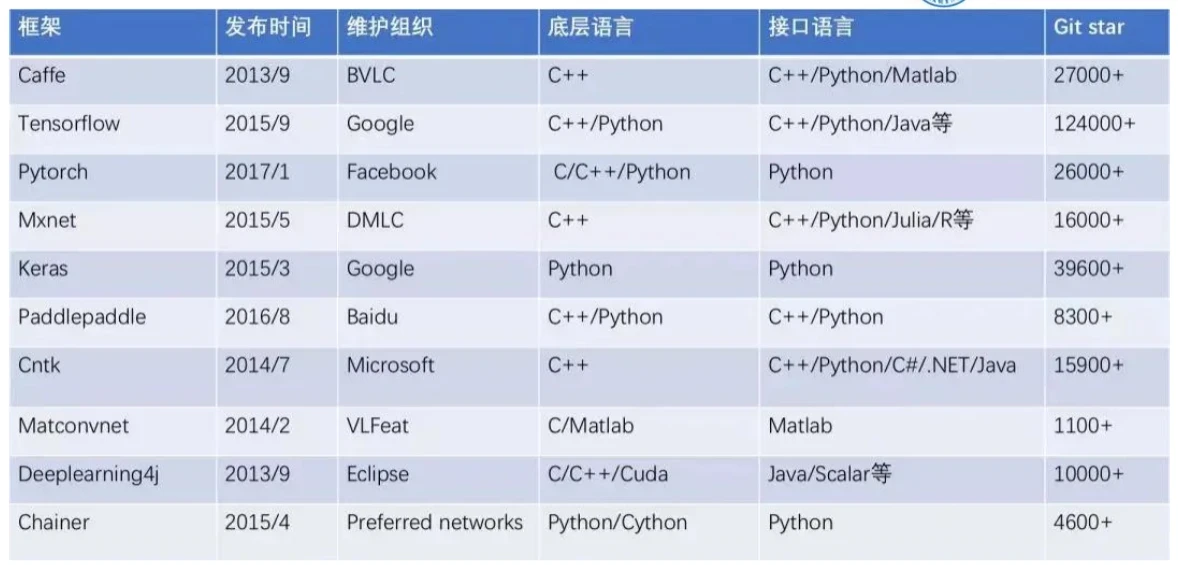
发展历程

各大框架的差异性
神经网络
是什么
深度学习是人工智能领域的一个热门技术,其基础是神经网络模型。神经网络模型是一种可以模拟人类大脑运作方式的计算模型,可以处理大量复杂的输入数据,并通过反向传播算法进行训练,从而实现复杂的分类、预测和识别等任务。
具体是什么
深度学习神经网络通常包含多个层次,包括输入层、隐藏层和输出层。输入层用于接收输入数据,隐藏层用于处理数据,输出层用于产生预测结果。每个层次包含多个神经元,神经元之间通过权重连接。
深度学习神经网络的训练过程通常使用反向传播算法,该算法通过调整权重来最小化模型的预测误差。反向传播算法需要使用损失函数和优化算法来进行训练。
应用在哪里
深度学习神经网络在计算机视觉、自然语言处理、语音识别等领域有广泛应用,例如图像分类、物体检测、机器翻译、情感分析等任务。
类别:感知机、神经网络模型训练和应用
- 以MNST数据集为例的数据集导入、分析和预处理,
- 然后构建多层感知机的神经网络模型
- 之后调整优化模型的计算和训练参数进行模型训练
- 最后对模型的性能进行评估
卷积神经网络
卷积神经网络是一种特殊的神经网络模型,其在计算机视觉和语音识别等领域有很好的应用。卷积神经网络的主要特点是其可以自动提取输入数据的特征,而不需要人为地进行特征工程。
卷积神经网络是一种特殊的神经网络模型,其主要用于处理二维图像数据。卷积神经网络包含卷积层、池化层和全连接层。
-
卷积层是卷积神经网络的核心,它通过使用多个卷积核对输入数据进行卷积操作,从而实现图像特征的提取。
卷积核可看作是一种过滤器,它可以提取图像中的边缘、纹理等特定类型的特征。
-
池化层通常紧接在卷积层后面,其主要用于对卷积层的输出进行下采样,从而减少数据量和计算量。常用的池化操作包括最大值池化和平均值池化。
-
全连接层通常位于卷积神经网络的末尾,其作用是将特征图压缩成一个一维向量,并将其输入到全连接层进行分类或回归等任务。
卷积神经网络在图像分类、目标检测、人脸识别等领域有较好的应用,例如AlexNet、VGG、ResNet等经典网络模型。
下面是一个使用 Keras 搭建卷积神经网络的示例代码。
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, ZeroPadding2D, Dropout, Flatten, Dense
model = Sequential()
model.add(Conv2D(48, (3,3), activation='relu', padding='same', input_shape=(224,224,3)))
model.add(Dropout(0.25))
model.add(MaxPooling2D((2,2)))
model.add(Conv2D(64, (3,3), activation='relu', padding='same'))
model.add(Dropout(0.25))
model.add(MaxPooling2D((2,2)))
model.add(Flatten())
model.add(Dense(1000, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4, activation='softmax'))
model.summary()
该卷积神经网络包括两个卷积层、两个池化层、一个 Flatten 层、一个隐藏层和一个输出层。其中,卷积层可以提取图像的特征,池化层可以对特征进行下采样,Flatten 层可以将特征图压缩成一维向量,隐藏层用于处理特征向量,输出层则用于进行分类。
详细案例
相册分类识别模型的训练过程
小结
深度学习神经网络和卷积神经网络是人工智能领域的重要技术,它们在计算机视觉、自然语言处理、语音识别等领域有广泛应用。深度学习神经网络由多个层次组成,可用于处理各种类型的数据;卷积神经网络则主要用于处理图像数据,其卷积层和池化层可以提取图像的特征并减少计算量。
更多参考:
批次大小batch_size由16升为64——准确率0.78
import numpy as np
from tensorflow.keras import models
from tensorflow.keras import layers
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import cv2
from tensorflow.keras.regularizers import L2
# 加载数据集
train_images = np.load("D:/Desktop/deeplearn/分类预测作业/课堂垃圾分类练习/upTo_81/trainImages.npy")
train_labels = np.load("D:/Desktop/deeplearn/分类预测作业/课堂垃圾分类练习/upTo_81/trainLabels.npy")
test_images = np.load("D:/Desktop/deeplearn/分类预测作业/课堂垃圾分类练习/upTo_81/testImages.npy")
test_labels = np.load("D:/Desktop/deeplearn/分类预测作业/课堂垃圾分类练习/upTo_81/testLabels.npy")
train_images = np.array([cv2.resize(img, (32, 32)) for img in train_images])
test_images = np.array([cv2.resize(img, (32, 32)) for img in test_images])
# 数据预处理
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
# 批次大小调整
train_generator = train_datagen.flow(x=train_images, y=train_labels, batch_size=64)
test_generator = test_datagen.flow(x=test_images, y=test_labels, batch_size=64)
# 搭建模型
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.BatchNormalization())
model.add(layers.Conv2D(32, (3, 3), activation='relu'))
model.add(layers.BatchNormalization())
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Dropout(0.25))
model.add(layers.Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Dropout(0.25))
model.add(layers.Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Dropout(0.25))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu', kernel_regularizer=L2(0.01))) # 添加 L2 正则化
model.add(layers.BatchNormalization())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(4, activation='softmax'))
# 编译模型(学习率调整)
model.compile(optimizer=Adam(lr=0.0005),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 设置检查点保存回调函数
checkpoint_callback = ModelCheckpoint(
filepath="./checkpoints/model.{epoch:02d}-{val_accuracy:.2f}.h5",
save_weights_only=False,
monitor='val_accuracy',
save_best_only=True)
# 训练模型(迭代次数调整)
history = model.fit(train_generator,
epochs=100,
validation_data=test_generator,
callbacks=[checkpoint_callback])
# 保存模型
model.save('D:/my_model.h5')
# 测试模型
test_loss, test_acc = model.evaluate(test_generator, verbose=2)
print('Test accuracy:', test_acc)
学习率进一步减小
lr=0.00025
但准确率没啥变化(但学习率变大就很差)
200就78
将迭代次数epoch升到200次,准确率下降到73了
改成50,更是下降到70了
改成150 降到70以下了
改成250还是0.78,只是貌似高了一点点
调到350直接降低到0.7
0.77
import numpy as np
from tensorflow.keras import models
from tensorflow.keras import layers
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import cv2
from tensorflow.keras.regularizers import L2
# 加载数据集
train_images = np.load("D:/Desktop/deeplearn/分类预测作业/课堂垃圾分类练习/upTo_81/trainImages.npy")
train_labels = np.load("D:/Desktop/deeplearn/分类预测作业/课堂垃圾分类练习/upTo_81/trainLabels.npy")
test_images = np.load("D:/Desktop/deeplearn/分类预测作业/课堂垃圾分类练习/upTo_81/testImages.npy")
test_labels = np.load("D:/Desktop/deeplearn/分类预测作业/课堂垃圾分类练习/upTo_81/testLabels.npy")
train_images = np.array([cv2.resize(img, (32, 32)) for img in train_images])
test_images = np.array([cv2.resize(img, (32, 32)) for img in test_images])
# 数据预处理
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
# 批次大小调整
train_generator = train_datagen.flow(x=train_images, y=train_labels, batch_size=64)
test_generator = test_datagen.flow(x=test_images, y=test_labels, batch_size=64)
# 搭建模型
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.BatchNormalization())
model.add(layers.Conv2D(32, (3, 3), activation='relu'))
model.add(layers.BatchNormalization())
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Dropout(0.25))
model.add(layers.Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Dropout(0.25))
model.add(layers.Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Dropout(0.25))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu', kernel_regularizer=L2(0.01))) # 添加 L2 正则化
model.add(layers.BatchNormalization())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(4, activation='softmax'))
# 编译模型(学习率调整)
model.compile(optimizer=Adam(lr=0.0001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 设置检查点保存回调函数
checkpoint_callback = ModelCheckpoint(
filepath="./checkpoints/model.{epoch:02d}-{val_accuracy:.2f}.h5",
save_weights_only=False,
monitor='val_accuracy',
save_best_only=True)
# 训练模型(迭代次数调整)
history = model.fit(train_generator,
epochs=200,
validation_data=test_generator,
callbacks=[checkpoint_callback])
# 保存模型
model.save('D:/my_model.h5')
# 测试模型
test_loss, test_acc = model.evaluate(test_generator, verbose=2)
print('Test accuracy:', test_acc)
更换模型,但这是根本无法完成的训练任务(太慢了)
import numpy as np
from tensorflow.keras import models
from tensorflow.keras import layers
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import cv2
from tensorflow.keras.regularizers import l2
from tensorflow.keras.applications import ResNet50
# 加载数据集
train_images = np.load("D:/Desktop/deeplearn/分类预测作业/课堂垃圾分类练习/upTo_81/trainImages.npy")
train_labels = np.load("D:/Desktop/deeplearn/分类预测作业/课堂垃圾分类练习/upTo_81/trainLabels.npy")
test_images = np.load("D:/Desktop/deeplearn/分类预测作业/课堂垃圾分类练习/upTo_81/testImages.npy")
test_labels = np.load("D:/Desktop/deeplearn/分类预测作业/课堂垃圾分类练习/upTo_81/testLabels.npy")
train_images = np.array([cv2.resize(img, (224, 224)) for img in train_images])
test_images = np.array([cv2.resize(img, (224, 224)) for img in test_images])
# 数据预处理
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
# 批次大小调整
train_generator = train_datagen.flow(x=train_images, y=train_labels, batch_size=64)
test_generator = test_datagen.flow(x=test_images, y=test_labels, batch_size=64)
# 搭建模型
base_model = ResNet50(include_top=False, weights='imagenet', input_shape=(224, 224, 3))
model = models.Sequential()
model.add(base_model)
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu', kernel_regularizer=l2(0.01)))
model.add(layers.BatchNormalization())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(4, activation='softmax'))
# 编译模型(学习率调整)
model.compile(optimizer=Adam(lr=0.0001), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 设置检查点保存回调函数
checkpoint_callback = ModelCheckpoint(
filepath="./checkpoints/model.{epoch:02d}-{val_accuracy:.2f}.h5",
save_weights_only=False,
monitor='val_accuracy',
save_best_only=True)
# 训练模型(迭代次数调整)
history = model.fit(train_generator,
epochs=200,
validation_data=test_generator,
callbacks=[checkpoint_callback])
# 保存模型
model.save('D:/my_model.h5')
# 测试模型
test_loss, test_acc = model.evaluate(test_generator, verbose=2)
print('Test accuracy:', test_acc)