正则表达式
参考笔记:
- 正则表达式入门笔记计算机愚蠢的地球人 (fairysoft.net)
- 正则表达式完整指南 (qq.com)
在线测试:正则表达式在线测试 | 菜鸟工具 (runoob.com) ^:开头$:结尾*:包含
踩坑记录
- 返回值只能是数组或null。详解正则表达式匹配方法 match() - 天天向上吧 - 博客园 (cnblogs.com)
?<=等报错,只有?=是正确的
创建正则表达式(JS)
其实主要是构成,其他语言只是API不同罢了,正则表达式是一门通用的语法(当然了在不同的语言和编辑器环境中可能出现一些细微的偏差,,。)
创建正则表达式的方式有两种:
-
字面量:正则表达式直接放在
/ /之中:const rex = /pattern/; -
构造函数:RegExp 对象表示正则表达式的一个实例:
const rex = new RegExp("pattern");
这两种方法的一大区别是对象的构造函数允许传递带引号的表达式,通过这种方式就可以动态创建正则表达式。通过这两种方法创建出来的 Regex 对象都具有相同的方法和属性:
let RegExp1 = /a|b/
let RegExp2 = new RegExp('a|b')
console.log(RegExp1) // 输出结果:/a|b/
console.log(RegExp2) // 输出结果:/a|b/
通过构造函数动态创建即可——>正则表达式中如何添加变量蒋不会的博客-CSDN博客正则表达式变量
模式匹配
字符集合
用 [] 表示,它会匹配包含的任意一个字符
想匹配 bat、cat 和 fat 这种类型的字符串——>/[bcf]at/ig
g是修饰符
字符范围
对于这种在一个范围中的字符, 就可以直接定义字符范围,用-表示。它用来匹配指定范围内的任意字符。这里就可以使用/[a-z]at/ig
常见的使用范围的方式如下:
- 部分范围:
[a-f],匹配 a 到 f 的任意字符; - 小写范围:
[a-z],匹配 a 到 z 的任意字符; - 大写范围:
[A-Z],匹配 A 到 Z 的任意字符; - 数字范围:
[0-9],匹配 0 到 9 的任意字符; - 符号范围:
[#$%&@]; - 混合范围:
[a-zA-Z0-9],匹配所有数字、大小写字母中的任意字符。
数量字符
匹配重复字符的完整语法是这样的:{m,n},它会匹配前面一个字符至少 m 次至多 n 次重复,
- {m}表示匹配 m 次,
- {m,}表示至少 m 次。
所以,当我们给5后面加上逗号时,就表示至少匹配五次——{5,}
除了可以使用大括号来匹配一定数量的字符,还有三个相关的模式:
+:匹配前面一个表达式一次或者多次,相当于{1,};*:匹配前面一个表达式0次或者多次,相当于{0,};?:单独使用匹配前面一个表达式零次或者一次,相当于{0,1},如果跟在量词*、+、?、{}后面的时候将会使量词变为非贪婪模式(尽量匹配少的字符),默认是使用贪婪模式。
使用/[a-z]+/ig就可以匹配任意长度的纯字母单词
注意事项:
一个中文汉子绝对不只是一次的任意字符[\S\s]的匹配!
因为中文的unicode字符表达是这样子的:
表示汉字的正则: [\u4e00-\u9fa5]
表示至少一个汉字的正则表达式:[1]
这才是一个汉字在正则匹配的时候识别的样子,所以绝对不只是一个字符!
js里边大概率是不支持?<=的,反正我已放弃!
参见:javascript正则表达式中 (?=exp)、(?<=exp)、(?!exp) - 华安 - 博客园 (cnblogs.com)
元字符
使用元字符可以编写更紧凑的正则表达式模式。说白了就是长串正则串表达式的简写形式
常见的元字符如下:(大写即为取反)
\d:相当于[0-9],匹配任意数字;\D:相当于[^0-9];\w:相当于[A-Z a-z 0-9_],匹配任意数字、大小写字母和下划线;\W:相当于:[^0-9a-zA-Z_];\s:相当于[\t\v\n\r\f],匹配任意空白符,包括空格,水平制表符\t,垂直制表符\v,换行符\n,回车符\r,换页符\f;\S:相当于[^\t\v\n\r\f],表示非空白符。
特殊字符
使用特殊字符可以编写更高级的模式表达式,常见的特殊字符如下:
.:匹配除了换行符之外的任何单个字符;\:将下一个字符标记为特殊字符、或原义字符、或向后引用、或八进制转义符;|:逻辑或操作符;[^]:取非,匹配未包含的任意字符。
例如
- 我们就是想要匹配
*怎么办?就可以使用\对其进行转义——>/ab\*/ - 开头和结尾是相同的,只有中间的两个字符是可选的。其实只需要给中间的或部分加上括号就可以了——>/s(ab|cd)z/
- 取非规则在范围中使用,例如
/[^a-z]/匹配到了所有非字母的字符
位置匹配
如果我们想匹配字符串中以某些字符结尾的单词,以某些字符开头的单词该如何实现呢?正则表达式中提供了方法通过位置来匹配字符:
\b:匹配一个单词边界,也就是指单词和空格间的位置;\B:匹配非单词边界;^:匹配开头,在多行匹配中匹配行开头;$:匹配结尾,在多行匹配中匹配行结尾;(?=p):匹配 p 前面的位置;(?!=p):匹配不是 p 前面的位置。
关于?号相关的位置匹配,更多参见:
正则表达式 – 语法 | 菜鸟教程 (runoob.com)
注意事项和精讲:
如何禁用零宽断言的方法——创建正则对象!
【正则】正则表达式-零宽断言(?=,?<=,?!,?<!)及常见报错 - Mila_媛儿 - 博客园 (cnblogs.com)
最常见的就是匹配开始和结束位置。
-
/^e/——以e开头 -
`
/e$/igm——以e结尾——需要注意,这里我们都使用m修饰符开启了多行模式。 -
/\w+$/——匹配每一行的最后一个单词 -
使用
/(?=the)/ig来匹配字符串中the前的面的位置 -
使用
\b来匹配单词的边界,匹配的结果如下: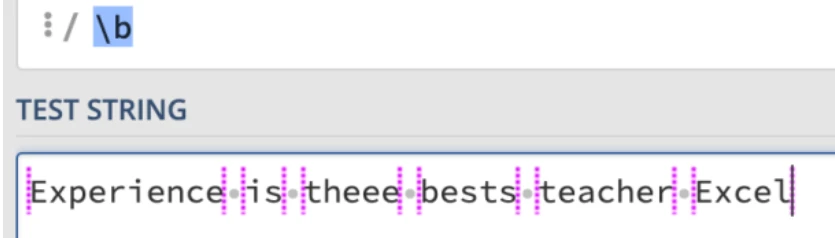
这可能比较难理解,我们可以使用以下正则表达式来匹配完整的单词:
\b\w+\b,匹配结果如下: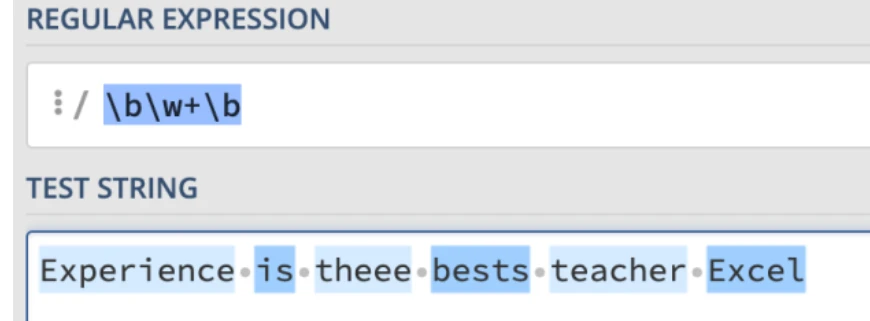
正则中文
常用的几种中文编码格式 :
- utf-8编码 utf-8又称“万国码”,可以同屏显示多语种,一个汉字通常占用3字节(生僻字占6个)。
- gb2312编码 简体中文编码,一个汉字占用2个字节,不支持繁体字
- gbk编码 GB2312的扩展,一个汉字占用2个字节,支持繁体字。
众所周知中文在计算机中是不能进行存储的。那我们是以什么办法让我们和计算机进行更好的沟通呢?
表示汉字的正则: [\u4e00-\u9fa5]
表示至少一个汉字的正则表达式:^[\u4e00-\u9fa5]
只含有汉字、数字、字母、下划线,下划线位置不限:^[a-zA-Z0-9_\u4e00-\u9fa5]+$
例一:匹配一个字符串是纯中文组成的字符串
var box = /^[\u4e00-\u9fa5]+$/;
alert(box.test("武汉加油"));//返回 true
例二:编写一个方法求一个字符串的字节长度,假设:一个英文字符占用一个字节,一个中文字符占用两个字节。
function strLength(str){
//判断中文,中文要单独进行计数
var count = 0;
//设置一个判断中文正则
var box = /^[\u4e00-\u9fa5]$/;
for(var i = 0; i < str.length; i++){
if(box.test(str[i])){
count++;
}
}
return str.length + count;
}
alert(strLength("中国加油cn"));//返回值是10
- \u4e00-\u9fa5 ↩︎