那些坑
镜像源之锅
其实不止啊里,以前在用npm、pip这些包管理工具也是有遇到类似的情况的,国内的镜像源还有清华、淘宝等,总之留点心吧,他们可能把非常古老的版本当做最新的拉下来然后启动出现一堆Bug,参考原文:docker运行cloudflare报错:Incorrect Usage: flag provided but not defined: -token_cloudflared
使用CloudFlare的Tunnels隧道服务的时候,使用docker启动cloudflare时发现一直起不来,查看日志发现报错:Incorrect Usage: flag provided but not defined: -token
原因:因为阿里源的问题(可能的原因之一)
解决:使用特定版本代替latest,如2023.5.0-amd64。如docker run cloudflare/cloudflared:2023.5.0-amd64 tunnel --no-autoupdate run --token XXX
当然也可以删除阿里源(这样可能比较慢,得用科学上网)
Command line is too long Shorten the command line and rerun
有时候想要将多个微服务,聚合成一个服务以一个Jar包进行启动,同时又加上了一堆VM参数,这会导致最终启动程序的命令行过长,导致IDEA结束(据说,该问题仅 Windows 系统电脑会出现)那如何解决?
可以使用 JAR 清单中的 Main-Class 属性来指定 Java 应用程序的入口点,并且可以在 JAR 清单中添加其他自定义属性,包括命令行参数。通过将长命令写入 Manifest.txt 文件,并在 JAR 清单中引用该文件,可以实现在启动应用程序时读取并执行该命令。
以下是一个示例,演示如何在 JAR 清单中引用 Manifest.txt 文件,并指定应用程序的入口点(Main-Class):
-
创建 Manifest.txt 文件,将您的长命令写入其中。假设您的命令是启动一个 Java 程序,命令行参数是
-Xmx512m -jar MyApp.jar,则 Manifest.txt 可能如下所示:Main-Class: com.example.MyMainClass Command-Line-Args: -Xmx512m -jar MyApp.jar -
使用 jar 命令创建 JAR 文件,并指定 Manifest.txt 作为 JAR 清单:
jar cmf Manifest.txt MyApp.jar com/* -
然后,您可以使用以下命令来启动应用程序:
java -jar MyApp.jar在这种情况下,Java 虚拟机将读取 JAR 清单中的 Main-Class 属性,并执行该类的 main 方法。您的应用程序可以在启动时读取 Manifest.txt 文件中的 Command-Line-Args 属性,并将其解析为命令行参数。
IDEA只要选择缩短命令行的方式为JAR manifest即可,具体步骤如下:
1)打开服务控制器。
选择聚合服务 AggregationServiceApplication,点击 Modify options,点击 shorten command line。
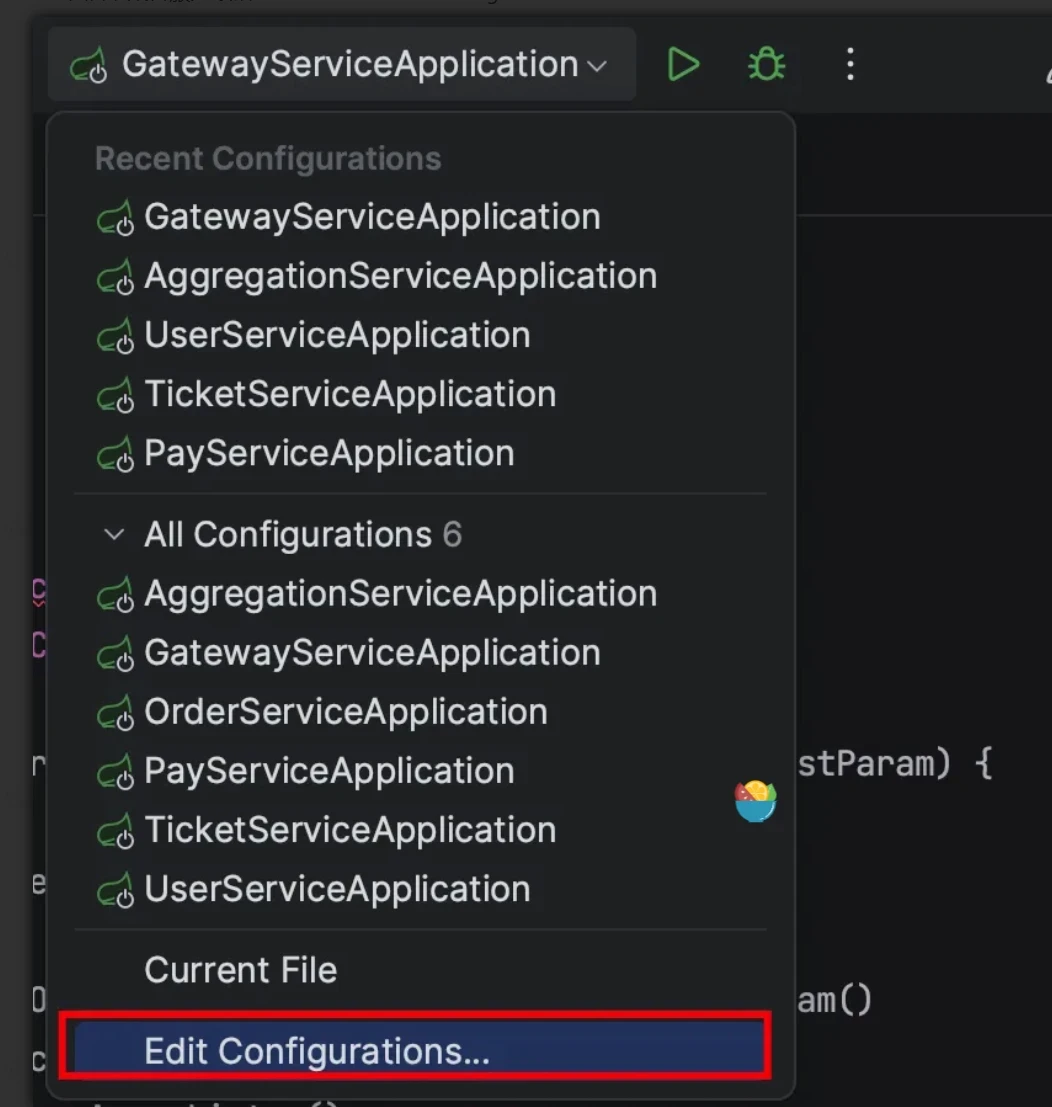
选择 JAR manifest,问题解决。
那些技巧
@RequiredArgsConstructor替代@Autowared和@Resource注解
@RequiredArgsConstructor
public class OrderServiceImpl implements OrderService {
private final OrderMapper orderMapper;
private final OrderItemMapper orderItemMapper;
.......
}
@RequiredArgsConstructor 是 Lombok 提供的一个注解,用于自动生成一个包含所有被 final 修饰的成员变量的构造函数,同时也会生成一个不带参数的构造函数。也就是Spring的构造器注入,在需要引入很多SpringBoot的Bean对象的时候,这种实现方法无疑优雅很多
Nginx压缩限流
Nginx传递公网ip
关闭Kdump
我买的服务器是2核4G,但运行两个微服务一段时间后直接死机了,。而且实际发现能用内存只有3.65G左右,这简直了。原来腾讯云服务器会启动kdump功能,为了出错后方便分析错误,但我不需要啊,我要内存!参考文章:解决云服务器开机后,内存与实际不符的问题-腾讯云开发者社区-腾讯云 (tencent.com)
首先,确保你了解Kdump的作用和重要性。Kdump是一种用于捕获Linux内核崩溃时的内存转储的机制,它可以帮助分析系统崩溃的原因。如果你决定关闭Kdump,确保你能接受在系统出现严重问题时无法获取详细的内存转储信息。
下面是你可以采取的步骤:
-
查看当前Kdump配置: 运行以下命令来查看当前系统中Kdump的配置:
cat /etc/default/grub确保其中是否有
crashkernel参数,以及其设置的值。 -
调整Kdump内存大小: 如果你希望调整Kdump所需的内存大小,你可以编辑
/etc/default/grub文件,并修改crashkernel参数的值。例如,如果你希望将内存大小调整为较小的值,可以将其设为crashkernel=64M。请注意,调整内存大小可能会影响Kdump的有效性。确保你对此有所了解,并根据实际情况进行调整。
-
更新GRUB配置: 完成调整后,运行以下命令来更新GRUB的配置文件:
sudo grub-mkconfig -o /boot/grub/grub.cfg -
重启服务器: 重启服务器以使新的GRUB配置生效:
sudo reboot -
验证Kdump状态: 在服务器重新启动后,验证Kdump是否已成功关闭或内存大小是否已调整:
sudo systemctl status kdump.service
通过以上步骤,你可以调整Kdump所需的内存大小,甚至关闭Kdump功能。请确保你理解这些操作的影响,并根据实际需要进行调整。
Java调用第三方程序
Java调用第三方程序:`Java.lang.ProcessBuilder
IDEA通过VM参数覆盖配置启动服务
IDEA配置VM参数覆盖配置文件启动服务
那些Bug
文件上传接口的请求和接收
近期接手一个需求,需求转成代码实现就是需要在一个接口实现很多参数传递的同时加上文件上传
原先问题的接口展示和故障说明:
@PostMapping ("/create")
public ApiResultBean postTest(HttpServletRequest request,
@RequestBody PayOrderCreateReqDto payOrderCreateReqDto,
@RequestParam (value = "applyFiles") MultipartFile applyFiles
这是一个简单的接口,接收一个body参数和一个文件参数,但是在前端调用的时候,报错如下: org.springframework.web.multipart.MultipartException: Current request is not a multipart request这个错误的意思是说,当前的请求不是一个multipart请求,也就是说,springboot无法识别这个请求的类型,无法正确地解析参数。
问题原因分析:为什么会出现这个问题呢?我们先来看一下springboot是如何处理参数的。springboot提供了几种常用的注解来接收参数,如下:
@RequestParam:用来接收普通的请求参数,如url中的query参数,或者表单中的键值对参数。@PathVariable:用来接收路径中的参数,如/user/{id}中的id参数。@RequestHeader:用来接收请求头中的参数,如Cookie,User-Agent等。@CookieValue:用来接收Cookie中的参数,相当于@RequestHeader("Cookie")。@RequestBody:用来接收请求体中的参数,一般用于接收json,xml等格式的数据,需要指定consumes属性来指明数据类型。
那么,MultipartFile是属于哪种参数呢? 答案是,它既不属于请求参数,也不属于请求体,而是属于请求的一部分,需要通过流的方式来获取。MultipartFile实际上是springmvc对文件上传的一个封装,它包含了文件的名字,类型,大小,内容等信息,可以通过transferTo,getInputStream,getBytes等方法来操作文件。 那么,既然MultipartFile是请求的一部分,为什么不能和@RequestBody一起使用呢? 这是因为,当我们使用@RequestBody的时候,springboot会使用HttpMessageConverter接口的实现类来转换请求体中的数据,比如MappingJackson2HttpMessageConverter,GsonHttpMessageConverter等,这些转换器会将请求体中的数据转换成对应的对象,比如json转成java对象,xml转成java对象等。而这个转换的过程,会导致请求体中的数据流被读取,从而导致无法再次读取请求体中的其他数据,比如文件数据。 所以,当我们同时使用@RequestBody和@RequestParam来接收文件时,就会出现上面的错误,因为springboot无法再从请求体中获取文件数据。
问题解决方案:既然我们知道了问题的原因,那么解决方案就很简单了,就是避免同时使用@RequestBody和@RequestParam来接收文件,而是使用其他的方式来接收参数和文件。这里介绍两种比较简单的方式:
-
方式一:使用多个@RequestParam来接收参数和文件:这种方式是最简单的,就是将所有的参数都用@RequestParam来接收,不使用@RequestBody,这样就可以避免请求体中的数据流被读取的问题。代码如下:
@PostMapping ("/create") public ApiResultBean postTest(HttpServletRequest request, @RequestParam (value = "applyFiles") MultipartFile applyFiles这种方式的优点是简单,缺点是如果参数比较多,就会显得很冗余,而且需要手动将参数转换成对象,比较麻烦。
-
方式二:使用json字符串和@RequestParam来接收参数和文件:这种方式是在方式一的基础上做了一些改进,就是将参数封装成一个json字符串,然后用@RequestParam来接收,然后再用gson等工具将json字符串转换成对象,这样就可以避免参数过多的问题,也可以避免请求体中的数据流被读取的问题。代码如下:
@PostMapping ("/create") public ApiResultBean postTest(HttpServletRequest request, @RequestParam (value = "dtoJson") String payOrderCreateReqDto, @RequestParam (value = "applyFiles") MultipartFile applyFiles PayOrderCreateReqDto toDto = gson.fromJson (payOrderCreateReqDto,PayOrderCreateReqDto.class);这种方式的优点是可以减少参数的数量,缺点是需要手动将json字符串转换成对象,而且需要前端配合将参数转换成json字符串。
注解顺序覆盖问题
增删注解的时候可以通过查看类结构代码来发现比较方便观察类属性和方法的变化
场景:使用@AllArgsConstructor注解的时候无参构造方法消失了
-
@Data注解默认提供无参构造
-
如若需要有参构造则使用:
@AllArgsConstructor -
但这会导致无参构造覆盖消失,解决办法末尾再追加`@NoArgsConstructor
-
所以最终结果就是:
@Data @AllArgsConstructor @NoArgsConstructor public class BaiDuTranslationVO extends Result { @ExcelProperty("序号") private int id; @ExcelProperty("文本") private String text; @ExcelProperty("翻译") private String trans; }
数据库中null就是null,不等于任何值
数据库中的null不等于任何值,包括自身,mp的eq传null底层会把sql写成where username=null,所以获取不到值,正确的查询语法只能用:
where username is null
代码里面的话mp则要写成wrapper.isNull(username)
超高像素图片的读取与内存
别看图片的大小不大,但实际上他是位存储,当加载进内存的时候会将其展开,一不小心就超过你的内存限制了
触发场景:海阔视界-图片读取(小棉袄debug)

本地仓库已经有对应的依赖,但是idea识别不到,maven爆红
原文:本地仓库已经有对应的依赖,但是idea识别不到,maven爆红_idea不从本地仓库-CSDN博客
结论:_remote.repositories的作用是当maven本地仓库缓存了jar/pom的情况下修改了maven的配置文件(settings.xml)后依然会去远程仓库获取。所以我们要做的就是:
删掉对应仓库坐标中的_remote.repositories文件即可!!!
清除_remote.repositories文件的脚本
set REPOSITORY_PATH=D:\JavaStudy\soft\MavenData\RepositoryData\repository
rem searching...
for /f "delims=" %%i in ('dir /b /s "%REPOSITORY_PATH%\*_remote.repositories*"') do (
del /s /q %%i
)
rem finished
pause
拷贝以上代码块,修改本地仓库地址后,存在txt文本文档里面,然后修改文档后缀为.bat
如此,双击该脚本文件即可删除仓库中所有_remote.repositories文件
未解之谜🎯
正常启动和debug模式的环境不等同
触发场景:Selenium启动浏览器时出现中断,怀疑是驱动问题
有些语句在debug正常执行 在启动模式就有问题和异常 实在找不到解决方法和原因的话,就在这个有问题的语句块上套一层try{}...catch{},就能执行通过了,。 但程序也的确会走入到catch中,但又不会影响后续的执行,这才是最神奇的!感觉就是怪!
那些混淆
@Transactional注解
如果在微服务项目中使用@Transactional注解,那么它通常用于确保单个服务内的数据一致性。在微服务架构中,每个服务通常都有自己的数据库,因此@Transactional注解的作用范围被限制在服务内部的事务管理。
在微服务环境中,即使服务之间是独立的,每个服务内部仍然可能存在需要事务管理的情况,例如:
- 在同一个服务中,需要对多个数据库操作进行原子性管理,确保这些操作要么全部成功,要么全部失败。
- 服务内部的方法调用可能涉及到对多个数据库表的更新,需要保证这些更新的原子性。
在这种情况下,@Transactional注解仍然是有用的,因为它可以确保服务内部的数据一致性。然而,它不适用于跨服务的事务管理,因为跨服务的事务涉及到多个独立的数据
数据脱敏不等同数据加密
这两者其实是两个概念!
敏感信息包括但不限于手机号码、身份证号、银行卡号等,这些信息泄露可能导致用户个人信息的滥用、身份盗用等严重问题。脱敏是一种常用的保护用户隐私的方式,它的目的是减少潜在的风险,同时保持一定的用户信息可读性。
而加密则是真的加密存储在数据库里边密文了,读取的时候必须通过秘钥和特定算法解密
(有很多现成的ORM框架都支持字段配置加解密规则)
至于数据脱敏有两种可选方案:
- AOP+自定义注解(比较重量级,而且涉及反射性能会差一些,而且需要做的工作很多)
- 在 SpringMVC 返回数据时,通过默认的 Jackson 序列化器进行指定,替换为咱们已经包装后的序列化器,这样就能依赖现有解决方案,降低技术复杂度。
一般,接口和实体对应的有返回真实数据也有返回脱敏结果的接口,实体里边包含真实和脱敏字段按需返回